PE do zero: navegando pelos headers (Parte 1)
Aviso: este post tem fins puramente educacionais. Entender a estrutura PE é conhecimento base pra qualquer coisa de reverse engineering, análise de malware, hooking e desenvolvimento de ferramentas de segurança. O mesmo conhecimento aplicado aqui é o que malware usa. A diferença é a intenção. Não ataque sistemas que não são seus.
Tava estudando IAT Hooking e em algum momento percebi que não entendia direito o que estava fazendo. Sabia que tinha que navegar pelo PE pra chegar na Import Table, mas não entendia o caminho de verdade. Resolvi parar e estudar a estrutura do PE do zero, com calma, campo por campo.
Esse post é meu caderno de anotações desse estudo. Diferente da série IAT Hooking que é mais referência, aqui a ideia é ir abrindo o CFF Explorer, apontar pra cada campo, e escrever o código que acessa aquele valor em tempo real. Aprender fazendo.
Essa é a Parte 1, onde a gente percorre toda a cadeia de headers: DOS Header, NT Headers, FileHeader, Sections e DataDirectory. Na Parte 2 a gente usa esse mapa pra converter RVA em offset real e finalmente chegar na Import Table de verdade, lendo os nomes de cada DLL e função importada.
Ferramenta que vou usar
Recomendo baixar o CFF Explorer da NTCore pra acompanhar. É gratuito e tem uma view visual de tudo que vamos ver no código.
Download: https://ntcore.com/explorer-suite/
Como cobaia eu vou usar o notepad.exe mesmo:
C:\Windows\System32\notepad.exe
Simples, acessível em qualquer Windows, e tem tudo que a gente precisa pra estudar.
1. DOS Header: o começo de tudo
Primeira coisa: abre o notepad.exe no CFF Explorer e clica em Dos Header.
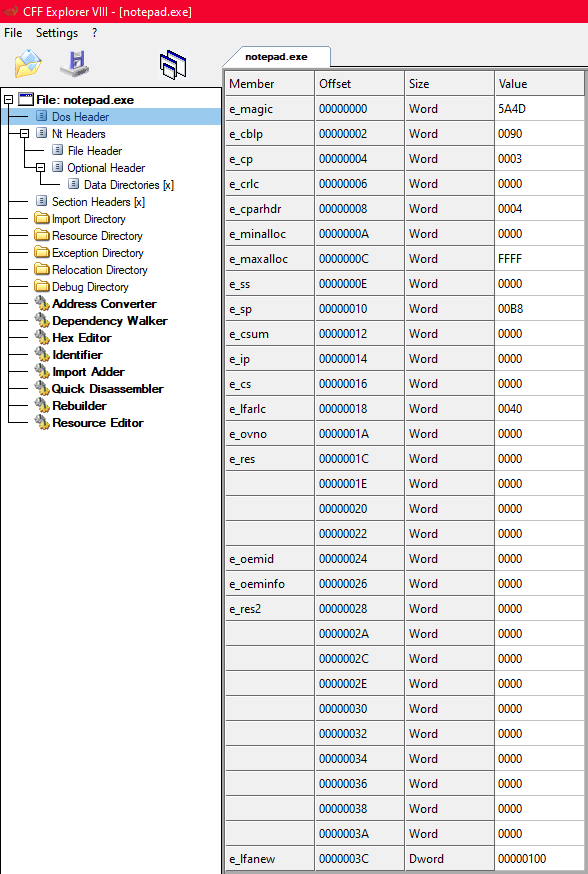
Tem uma lista enorme de campos ali, mas de início só dois importam:
e_magic: vale 0x5A4D, que em ASCII é "MZ". São as iniciais de Mark Zbikowski, o engenheiro da Microsoft que projetou o formato executável do MS-DOS nos anos 80. Todo arquivo PE válido começa com esse valor. É a primeira coisa que qualquer parser verifica pra confirmar que está lidando com um executável Windows de verdade.
e_lfanew: esse campo guarda o offset de onde começa o cabeçalho NT, em bytes a partir do início do arquivo. No notepad vale 0x100. Pensa nele como uma ponte: o DOS Header está ali só por compatibilidade histórica, mas ele aponta pra onde o PE de verdade começa. Sem ele não teria como saber onde pular.
Vamos acessar esses dois valores no código:
HMODULE proc = GetModuleHandle(NULL); // base address do processo atual
PIMAGE_DOS_HEADER dos = (PIMAGE_DOS_HEADER)proc;
cout << "Magic: 0x" << hex << dos->e_magic << endl;
cout << "e_lfanew: 0x" << hex << dos->e_lfanew << endl;
GetModuleHandle(NULL) retorna o endereço base do módulo atual, que é o .exe que está rodando. A gente faz um cast pra PIMAGE_DOS_HEADER porque o executável começa exatamente com essa struct, então o ponteiro já aponta pro lugar certo desde o início.
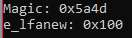
Bate exatamente com o que o CFF Explorer mostrou.
Uma observação importante aqui: o GetModuleHandle(NULL) retorna o base address do meu próprio exe, o que compilei e estou rodando. Nao do notepad. O CFF Explorer com o notepad aberto é só pra ter uma referência visual dos campos, entender o que cada um representa. Por isso os valores no console podem ser diferentes dos que aparecem no CFF, sao binários diferentes rodando.

2. NT Headers: a assinatura PE
Agora que tenho o e_lfanew, posso pular pra próxima camada. Clica em Nt Headers no CFF Explorer:
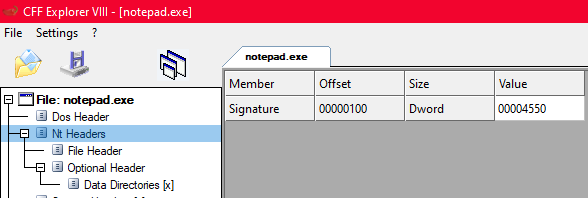
Só um campo visível aqui: Signature com valor 0x00004550. Em ASCII isso é "PE\0\0". É a segunda verificação que qualquer parser faz. DOS Header começa com MZ, NT Headers começa com PE. Dois checks simples que confirmam que você está lidando com um executável Windows válido.
Pra chegar aqui no código, a gente pega o base address, soma o e_lfanew e faz o cast:
PIMAGE_NT_HEADERS32 nt = (PIMAGE_NT_HEADERS32)((BYTE*)proc + dos->e_lfanew);
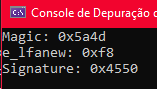
cout << "Signature: 0x" << hex << nt->Signature << endl;
Por que (BYTE*)proc + dos->e_lfanew? Porque aritmética de ponteiro em C++ depende do tipo. Se você somar direto em HMODULE, o compilador não sabe o tamanho do passo. Fazendo o cast pra BYTE* primeiro, cada unidade de soma é exatamente 1 byte, aí somar e_lfanew te leva ao offset exato dentro do binário.
Vale notar uma coisa sobre a struct que usei: PIMAGE_NT_HEADERS32. Se o seu projeto estiver compilado como x64, basta trocar por PIMAGE_NT_HEADERS64. Ou você pode usar PIMAGE_NT_HEADERS direto, que o próprio compilador resolve pra versao certa dependendo da arquitetura alvo. Pra esse estudo estou compilando em x86 pra manter mais simples.

3. FileHeader: metadados do executável
O NT Headers tem três partes dentro dele:
IMAGE_NT_HEADERS
│
├── Signature
├── FileHeader ← estamos aqui
└── OptionalHeader
O FileHeader guarda informações gerais sobre o executável. Clica em File Header no CFF Explorer:
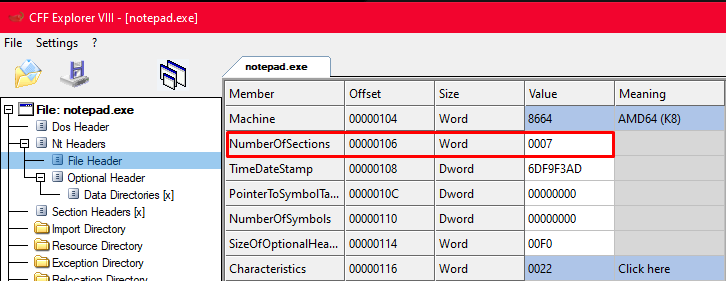
Tem vários campos ali. Os que mais me interessaram:
Machine: a arquitetura do binário. 0x8664 significa AMD64 (x86-64). Se fosse 0x14C, seria x86 32 bits. É a primeira coisa que um loader verifica pra saber se consegue rodar o executável na máquina atual.
NumberOfSections: quantas seções o executável tem. Pensa assim: o exe é dividido em pedaços, cada pedaço com uma função específica: .text pro código, .data pras variáveis, .rdata pra dados somente leitura. Esse número me diz quantos pedaços existem. Vou precisar dele logo mais pra iterar por todos.
TimeDateStamp: quando o binário foi compilado. Curiosidade: malwares costumam falsificar esse campo pra esconder a origem. Se você encontrar um exe com timestamp de 1970, desconfie.
Characteristics: um campo de flags que descreve o tipo do binário. É DLL? É EXE? Tem debug symbols? Cada bit tem um significado diferente.
O campo que vou usar agora é o NumberOfSections. Pra acessar:
cout << "NumberOfSections: " << dec << nt->FileHeader.NumberOfSections << endl;
nt->FileHeader funciona assim: nt já aponta pro NT Headers na memória. ->FileHeader diz pro compilador “entra no campo FileHeader dessa struct”. E NumberOfSections é o campo que quero ler. É basicamente navegar por camadas: NT Headers → FileHeader → campo específico.
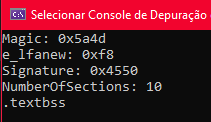
Saiu o número certinho. É exatamente esse valor que vou usar como limite no loop de seções.
Como o C++ sabe onde o FileHeader começa?
Mas aqui eu tive uma dúvida: como nt->FileHeader sabe o endereço exato na memória? Eu nao passei nenhum ponteiro pra ele.
O Windows definiu a struct IMAGE_NT_HEADERS com os campos numa ordem exata e fixa. O layout real fica assim:
offset +0 Signature (4 bytes)
offset +4 FileHeader (20 bytes)
offset +24 OptionalHeader (variável)
Quando você escreve nt->FileHeader, o compilador calcula automaticamente “4 bytes depois do início da struct”. Sem mágica nenhuma, é só aritmética de struct. E como essa ordem nunca muda (é parte do formato PE há décadas), você pode contar com ela sempre.
4. Section Headers: as partes do executável
Um executável PE é dividido em seções, cada uma com uma função específica:
| Seção | Conteúdo |
|---|---|
.text | código executável |
.data | variáveis globais com valor inicial |
.rdata | dados somente leitura (strings, tabela de imports) |
.bss | variáveis não inicializadas |
.rsrc | recursos (ícones, imagens, strings de UI) |
Cada seção tem um cabeçalho (IMAGE_SECTION_HEADER) que descreve onde ela está e quanto espaço ocupa. A tabela de seções fica logo depois do IMAGE_NT_HEADERS na memória. Nao existe outro ponteiro pra encontrá-la, ela simplesmente começa imediatamente após.
Pra acessar a primeira seção existe uma macro do Windows SDK feita exatamente pra isso. Antes de ver o código, preciso apresentar dois campos que vão aparecer o tempo todo a partir daqui:
VirtualAddress: o RVA onde essa seção começa quando o executável está carregado na memória. Nao é onde ela fica no arquivo em disco, é onde ela fica na memória depois que o Windows carregou tudo.
PointerToRawData: o offset onde essa seção começa no arquivo em disco. É o endereço físico de verdade, sem virtualização nenhuma.
Por que os dois existem separados? Porque o Windows reorganiza o executável ao carregar na memória. O que está num offset no arquivo pode estar num endereço completamente diferente na memória. Esses dois campos juntos sao o que a gente usa pra fazer essa conversão, como vai ficar claro na seção sobre RVA logo abaixo.
Agora sim, o código pra acessar a primeira seção:
PIMAGE_SECTION_HEADER section = IMAGE_FIRST_SECTION(nt);
cout << "Name : " << section->Name << endl;
cout << "VirtualAddress : 0x" << hex << section->VirtualAddress << endl;
cout << "PointerToRawData : 0x" << hex << section->PointerToRawData << endl;
IMAGE_FIRST_SECTION(nt) calcula onde a primeira seção começa somando o tamanho do NT Headers ao ponteiro nt. Dai section->Name é o nome, section->VirtualAddress é o RVA na memória, e section->PointerToRawData é o offset no arquivo.
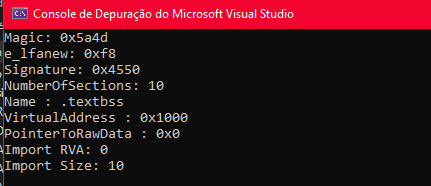
Apareceu o nome e os dois endereços. Bate com as colunas Virtual Address e Raw Address que o CFF Explorer mostra na aba Section Headers.
Iterando por todas as seções
Mostrar só a primeira seção é útil pra entender a struct, mas na prática a gente precisa percorrer todas. É simples: NumberOfSections já tem a quantidade exata, e as seções ficam em sequência na memória logo depois do NT Headers, entao dá pra acessar como array mesmo:
WORD numSections = nt->FileHeader.NumberOfSections;
PIMAGE_SECTION_HEADER sections = IMAGE_FIRST_SECTION(nt);
for (WORD i = 0; i < numSections; i++) {
cout << "Name : " << sections[i].Name << endl;
cout << "VirtualAddress : 0x" << hex << sections[i].VirtualAddress << endl;
cout << "PointerToRawData : 0x" << hex << sections[i].PointerToRawData << endl;
cout << "---" << endl;
}
sections[i] funciona exatamente como um array normal porque os IMAGE_SECTION_HEADER ficam um do lado do outro na memória. Na Parte 2 esse loop vai ser o coração da conversao RVA → offset: a gente itera pelas seções, verifica qual delas contém o RVA que estamos procurando, e usa o PointerToRawData pra calcular o offset real.
O que é RVA?
Antes de avançar pro Optional Header e DataDirectory, precisei parar pra entender um conceito que aparece em todo lugar: RVA (Relative Virtual Address, endereço virtual relativo).
RVA é um endereço relativo à ImageBase do módulo. A ImageBase é o endereço onde o Windows carregou o executável na memória. O RVA sozinho não diz onde algo está, você precisa somá-lo à ImageBase pra ter o endereço absoluto:
ImageBase = 0x140000000
RVA = 0x1000
VA = 0x140001000
Por que isso existe? Por causa do ASLR (Address Space Layout Randomization): o Windows carrega executáveis em endereços diferentes a cada execução. Hardcodar endereços absolutos dentro do PE não funciona. Então o formato armazena tudo como offsets relativos, e quem carrega o binário resolve os endereços reais na hora.
RVA nao e offset no arquivo
Esse foi o ponto que mais me confundiu: um RVA diz onde algo está na memória, mas nao diz onde está no arquivo em disco. O Windows reorganiza o executável quando carrega, então o que está no offset 0x400 no arquivo pode estar no endereço virtual 0x1000 quando carregado.
Pra ler algo pelo RVA diretamente no arquivo (sem ter o binário mapeado na memória), você precisa converter RVA em offset real. Isso é feito usando as seções como tabela de conversão. Cada seção sabe:
VirtualAddress = RVA onde a seção começa na memória
PointerToRawData = offset onde a seção começa no arquivo
Então a conversão fica:
rawOffset = PointerToRawData + (RVA - VirtualAddress)
Exemplo: você quer algo no RVA 0x1200. A seção .text vai de RVA 0x1000 até 0x2000, com PointerToRawData = 0x400:
rawOffset = 0x400 + (0x1200 - 0x1000) = 0x600
Esse cálculo é o coração do PE parsing quando você trabalha com o arquivo em disco. Na Parte 2 a gente implementa exatamente isso pra chegar na Import Table.

5. Optional Header e DataDirectory
Apesar do nome, o Optional Header nao e opcional em executáveis. Dentro dele tem um campo que é o destino de tudo que a gente está fazendo: o DataDirectory.
Pensa no DataDirectory assim: é um índice central com 16 entradas, onde cada entrada é um ponteiro pra uma tabela diferente dentro do PE. Cada entrada guarda dois valores simples: o RVA de onde aquela tabela começa, e o tamanho dela em bytes. Só isso. Mas é ele que conecta o cabeçalho com todo o conteúdo do executável.
DataDirectory[0] → Export Table
DataDirectory[1] → Import Table ← essa nos interessa
DataDirectory[2] → Resource Table
DataDirectory[5] → BaseReloc Table
...
Eu quero chegar na Import Table, que fica no índice 1. O Windows SDK já define uma constante pra isso: IMAGE_DIRECTORY_ENTRY_IMPORT. Ela vale literalmente 1, mas usar o nome deixa o código mais legível do que escrever DataDirectory[1] na mão.
Clico em Optional Header → Data Directories no CFF Explorer pra ver esses valores antes de codar:
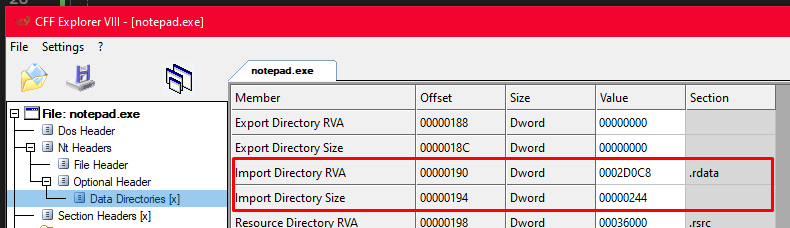
Repara que o Import Directory tem um RVA diferente de zero e um Size. Aquele RVA é o endereço relativo de onde a tabela de imports começa na memória. Agora vou pegar esse valor no código:
IMAGE_DATA_DIRECTORY importDir =
nt->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT];
cout << "Import RVA: 0x" << hex << importDir.VirtualAddress << endl;
cout << "Import Size: " << dec << importDir.Size << endl;
nt->OptionalHeader entra no OptionalHeader do NT Headers. Dai .DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT] pega a entrada de índice 1. E .VirtualAddress lê o RVA de onde a Import Table começa.
Apareceu o RVA da Import Table. Mas esse valor sozinho ainda nao me leva a lugar nenhum. Pra chegar na IMAGE_IMPORT_DESCRIPTOR de verdade preciso converter esse RVA em offset real usando as seções, exatamente o cálculo que vimos na seção do RVA. Isso fica pra Parte 2.
6. Tabela de seções no CFF Explorer
Agora que entendo o que VirtualAddress e PointerToRawData significam, clico em Section Headers no CFF Explorer e a tabela faz muito mais sentido do que faria antes:
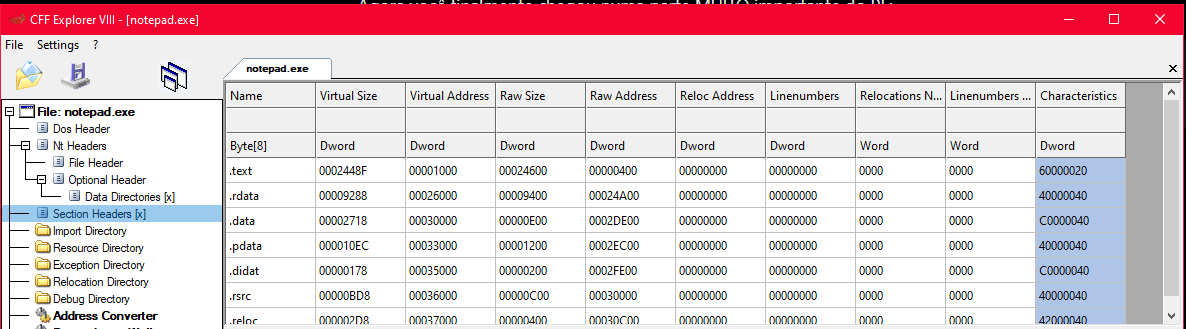
Cada linha é uma seção. Cada coluna:
| Coluna | Significado |
|---|---|
| Name | nome da seção (até 8 bytes) |
| Virtual Size | tamanho real do conteúdo na memória |
| Virtual Address | RVA onde a seção começa na memória (section->VirtualAddress) |
| Raw Size | tamanho no arquivo, arredondado pro FileAlignment |
| Raw Address | offset da seção no arquivo em disco (section->PointerToRawData) |
| Reloc Address / Linenumbers | raramente usados em binários modernos |
| Characteristics | flags de permissão da página |
As colunas Virtual Address e Raw Address sao exatamente os campos que o código imprimiu antes. O CFF Explorer está mostrando visualmente o mesmo dado que section->VirtualAddress e section->PointerToRawData acessam. Agora entendo o que cada linha representa e por que vou precisar desses valores na Parte 2.
Uma coisa que chama atenção nas Characteristics: 60000020 no .text significa executável + legível + contém código. 40000040 no .rdata significa somente leitura + contém dados inicializados. É por isso que pra fazer IAT hooking você precisa do VirtualProtect, a IAT fica na .rdata que é read-only por padrão. Tentar escrever direto lança uma exceção de proteção de memória.
Onde chegamos
Cobri toda a cadeia de headers do PE:
IMAGE_DOS_HEADER
└── e_lfanew → IMAGE_NT_HEADERS
├── Signature
├── IMAGE_FILE_HEADER
│ └── NumberOfSections
├── IMAGE_OPTIONAL_HEADER
│ └── DataDirectory[1] → Import Table RVA
└── IMAGE_SECTION_HEADER[]
├── .text
├── .rdata
├── .data
└── ...
Na Parte 2 a gente usa esse mapa pra:
- Converter o RVA da Import Table em offset real usando as seções
- Ler os
IMAGE_IMPORT_DESCRIPTOR, um pra cada DLL importada - Acessar os nomes das DLLs e das funções dentro de cada descriptor
- Imprimir tudo:
kernel32.dll → CreateFileW, ReadFile...
Post da série pe-do-zero, minhas anotações de estudo sobre PE parsing. Se achou algum erro ou tem sugestão, manda aí.